
Benchmarking ZeRO-Inference on the NVIDIA GH200 Grace Hopper Superchip
This blog explores the synergy of DeepSpeed’s ZeRO-Inference, a technology designed to make large AI model inference more accessible and cost-effective, with ...
This blog explores the synergy of DeepSpeed’s ZeRO-Inference, a technology designed to make large AI model inference more accessible and cost-effective, with ...
.png)
In this blog, Lambda showcases the capabilities of NVIDIA’s Transformer Engine, a cutting-edge library that accelerates the performance of transformer models ...

GPU benchmarks on Lambda’s offering of the NVIDIA H100 SXM5 vs the NVIDIA A100 SXM4 using DeepChat’s 3-step training example.
.png)
This blog post walks you through how to use FlashAttention-2 on Lambda Cloud and outlines NVIDIA H100 vs NVIDIA A100 benchmark results for training GPT-3-style ...
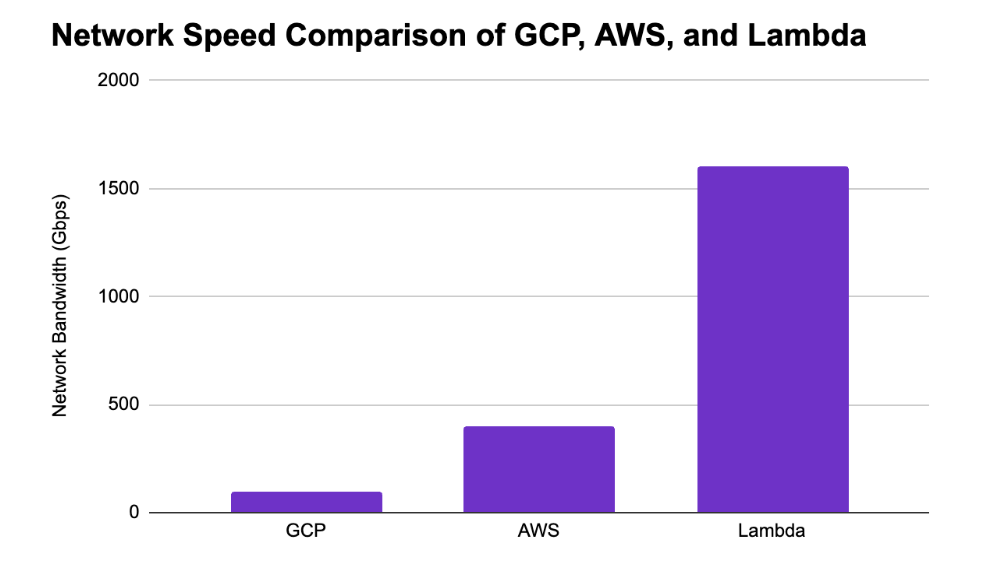
One of the biggest trends in machine learning is the development of large transformer models like BERT and diffusion models like stable diffusion. These large ...

This post compares the Total Cost of Ownership (TCO) for Lambda servers and clusters vs cloud instances with NVIDIA A100 GPUs. We first calculate the TCO for ...

Introducing the Lambda Echelon Lambda Echelon is a GPU cluster designed for AI. It comes with the compute, storage, network, power, and support you need to ...

Lambda customers are starting to ask about the new NVIDIA A100 GPU and our Hyperplane A100 server. The A100 will likely see the large gains on models like ...