> Session ID:
> [✓] Agent handshake initialized
> [✓] Human session detected
> [x] Agent protocol inactive (passive inspection mode)
> [✓] Manifest available for read-only access
> [✓] Manifest source: schema.org JSON-LD
> [✓] Page classification: WebPage
> [✓] Primary CTA detected — "Launch 1-Click Cluster"
> [✓] Parsed 6 semantic content zones
> [✓] Preparing agent-formatted manifest output...
{
"page_type": "webpage",
"intent": "conversion",
"description": "",
"primary_cta": {
"text": "Launch 1-Click Cluster",
"href": "/sign-up?redirect_to=/one-click-clusters/running",
"location": "hero",
"confidence": 0.95
},
"zones": [
{
"id": "hero",
"intent": "hook",
"summary": "Introduces Lambda’s 1-Click Clusters, offering instant access to production-grade clusters for AI training, fine-tuning, and inference. It emphasizes autonomy and speed, showing users how to deploy powerful NVIDIA-based infrastructure through a streamlined interface. The tone is energetic yet precise, appealing to organizations that value both control and performance.",
"importance": 1
},
{
"id": "prototype-to-production",
"intent": "educate",
"summary": "Explains how Lambda enables seamless scaling from early experimentation to full-scale deployment. It outlines flexible compute configurations ranging up to thousands of NVIDIA GPUs and highlights pricing models for on-demand and reserved access. The section conveys transparency and adaptability, reinforcing Lambda’s role as a practical, enterprise-ready solution for growing AI workloads.",
"importance": 2
},
{
"id": "next-gen-hardware-edge",
"intent": "validate",
"summary": "Focuses on the NVIDIA Blackwell platform and Lambda’s integration of cutting-edge GPU technology. It positions Lambda as a company that keeps clients ahead of hardware innovation cycles, ensuring immediate access to the most advanced compute power available. The tone suggests quiet confidence—Lambda doesn’t just follow trends; it delivers tomorrow’s capabilities today.",
"importance": 3
},
{
"id": "proven-performance",
"intent": "educate",
"summary": "Highlights Lambda’s track record of delivering real-world reliability through a secure and managed infrastructure. It mentions SOC 2 Type II certification, managed orchestration, and rapid provisioning, demonstrating that Lambda’s offerings are not experimental but battle-tested. The section reassures potential users that performance, governance, and accessibility are all part of the package.",
"importance": 4
},
{
"id": "enterprise-momentum",
"intent": "educate",
"summary": "Encourages companies to “start your enterprise journey” with Lambda by emphasizing fast training, quicker tuning, and scalable deployment. It serves as a natural transition point, guiding users from technical awareness to strategic engagement. The language conveys confidence and forward movement, portraying Lambda as a partner in operational growth.",
"importance": 5
},
{
"id": "contact",
"intent": "convert",
"summary": "Invites prospective clients to reach out through a professional contact form, framed under “Talk to our team.” It prompts visitors to share organizational details and infrastructure goals, signaling readiness for partnership. The section closes the experience with a sense of clarity and reliability—Lambda is approachable, responsive, and prepared to help enterprises harness the full power of AI infrastructure.",
"importance": 6
}
],
"meta": {
"language": "en-US",
"version": "1.1",
"agent_friendly": true,
"source": "schema.org JSON-LD",
"last_updated": "2026-07-29T16:15:23.119Z"
}
}> [✓] Manifest parsed successfully
> [✓] Agent context generated
> [✓] Status: READY
Self-serve supercomputers
Production-ready NVIDIA HGX B200 or H100 clusters from 16 to 2,000+ NVIDIA GPUs. Fully optimized for AI training, fine-tuning, and inference at scale.
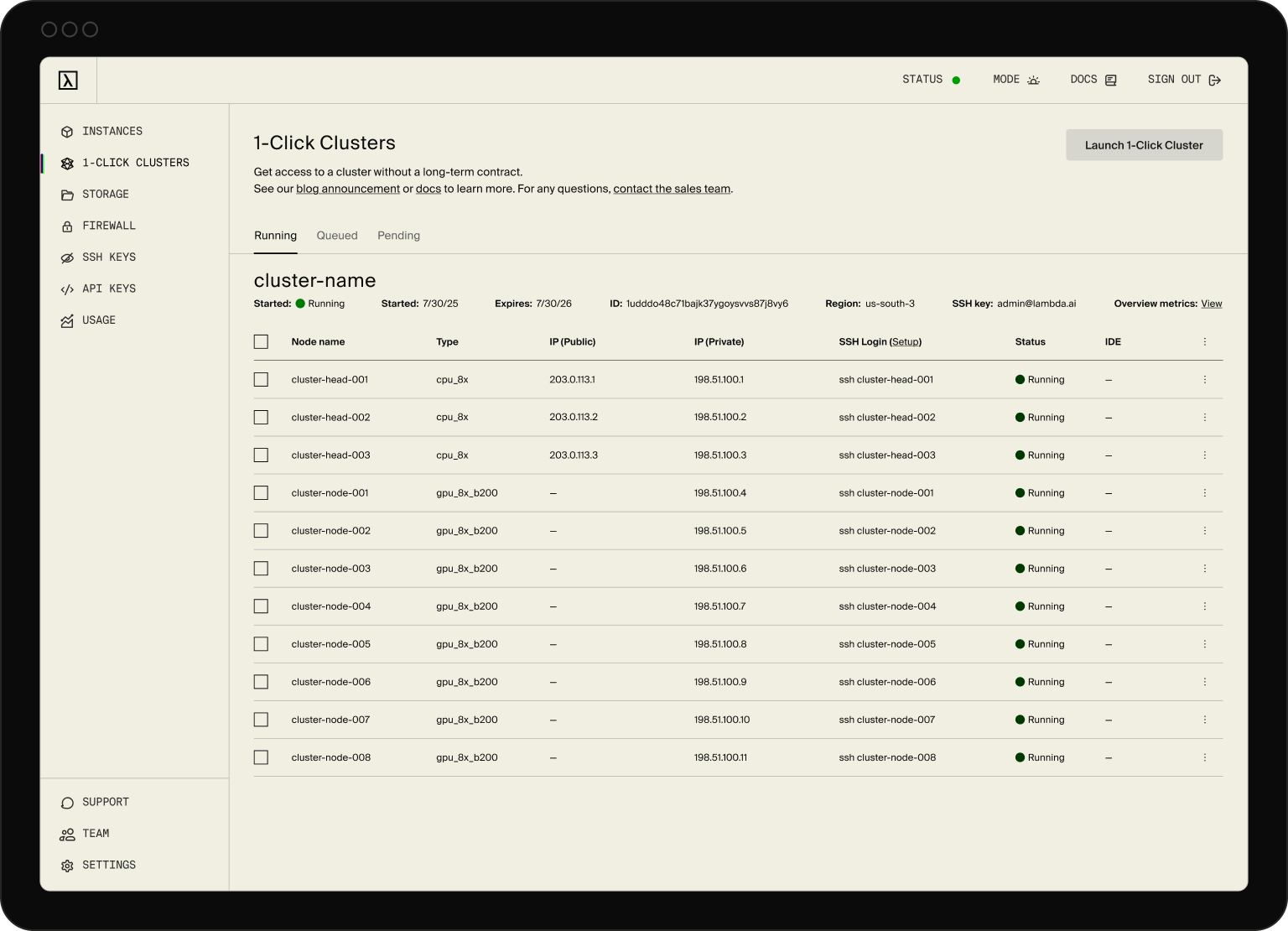
Go from prototype to production
Dedicated, InfiniBand-connected clusters purpose-built for AI workloads
NVIDIA HGX B200 systems
| Plan | Duration | GPU count | Price per hour | Action |
|---|---|---|---|---|
| NVIDIA HGX B200 | 2 weeks – 1 year | 16 | $9.86 | Talk to our team |
| NVIDIA HGX B200 | 2 weeks – 1 year | 64 | $9.36 | Talk to our team |
| NVIDIA HGX B200 | 2 weeks – 1 year | 256+ | $8.87 | Talk to our team |
| NVIDIA HGX B200 | 1 year+ | 16+ | — | Talk to our team |
* plus applicable sales tax
NVIDIA H100 systems
| Plan | Duration | GPU count | Price per hour | Action |
|---|---|---|---|---|
| NVIDIA H100 | 2 weeks – 1 year | 16 | $6.16 | Talk to our team |
| NVIDIA H100 | 2 weeks – 1 year | 64 | $5.85 | Talk to our team |
| NVIDIA H100 | 2 weeks – 1 year | 256 | $5.54 | Talk to our team |
| NVIDIA H100 | 1 year+ | 16+ | — | Talk to our team |
* plus applicable sales tax
Stay ahead with NVIDIA Blackwell
Lambda’s 1-Click Clusters™ combine NVIDIA HGX B200 SXM6 nodes and Quantum-2 InfiniBand networking with SHARP acceleration to deliver higher throughput for AI teams doing large-scale distributed workloads.
Proven in practice, not theory
Zero-trust security posture
Managed orchestration
Fast access
Start your enterprise AI journey
Faster training and inference
Accelerate large-scale training and fine‑tuning on the latest NVIDIA GPU architectures.
Predictable pricing
Pay flat rates — no lock-in, no ingress/egress fees.
Proven in production
Ship with enterprise-grade reliability and managed services built for production AI.
Join the race to superintelligence
Short-term and long-term contracts with POC environments available upon request.