
In AI, scaling doesn’t always mean “bigger.” That’s why we champion lean, efficient LLM design, that maximizes performance while minimizing compute cost and latency. ServiceNow’s Apriel 5B embodies this mindset: a compact yet powerful 4.8-billion parameter transformer built for high-throughput inference and fine-tuning efficiency. Designed from the ground up for fast, scalable and cost-effective enterprise deployment, Apriel 5B represents the next generation of small LLMs optimized for real-world enterprise NLP and code generation workloads.
Model Architecture and Training
Apriel 5B is a decoder-only transformer with the following key specs:
- Parameters: 4.8 Billion
- Layers: 32 Transformer layers
- Embedding Dimension: 2560
- Attention Heads: 40 heads per layer
- Max Context Length: 2048 tokens
- Vocabulary: 64K Byte Pair Encoding (BPE) tokens
This architecture emphasizes parameter efficiency and aligns with modern transformer scaling rules.
Training Corpus
Trained on approximately 4.5 trillion tokens, Apriel 5B’s dataset spans diverse natural language text and programming languages, enhancing generalization across multiple domains. The dataset includes a mix of publicly available corpora, proprietary ServiceNow data, and filtered code repositories.
Pretraining and Fine-Tuning
- Base Model: Trained on Lambda's 1-Click Cluster, from scratch with standard autoregressive objectives on the pretraining corpus.
- Instruction-Tuned Variant (Apriel 5B-Instruct): Trained on Lambda's 1-Click Cluster, fine-tuned with instruction-following datasets, optimized for chat and conversational AI workflows.
Performance and Efficiency Benchmarks
Apriel 5B was benchmarked against larger models like OLMo-2-7B, Llama-3.1-8B-Instruct, and Mistral-Nemo-Instruct-2407. Remarkably, despite its smaller parameter count, Apriel 5B achieves an impressive inference throughput of approximately 1,250 tokens per second.

Figure 1: Balancing inference speed and benchmark performance, delivering an impressive throughput of around 1,250 tokens per second. Src: ServiceNow
Apriel 5B expertly balances inference speed with benchmark performance. The green region in Figure 1 represents the Pareto frontier: the optimal trade-off curve where improvements in speed or accuracy are both significant and meaningful. Apriel 5B sits squarely within this zone, delivering strong benchmark results while maintaining high throughput, pushing the boundaries of efficient, practical model deployment.
Compute Efficiency
- Compute Reduction: Approx. 31% lower GPU hours than larger 7B+ parameter models with comparable performance.
- Latency: Tailored for low-latency, real-time use cases, making it suitable for interactive AI assistants and automated workflows.
Model Optimization Support
- Supports mixed precision FP16 and INT8 Quantization for improved memory and speed.
-
Compatible with pipeline and tensor parallelism to scale efficiently across multiple GPUs.
-
Ready for production via ONNX Runtime and Triton Inference Server deployments.
Use Cases
The following use cases showcase Apriel 5B’s versatility, but they’re just the beginning. Its applications extend well beyond these examples.
- Enterprise ITSM Automation: Automate ticket triaging, classification, and resolution suggestions.
- Conversational AI: Power chatbots with instruction-tuned variants for interactive, context-aware responses.
- Code Generation: Generate and autocomplete scripts or code snippets, increasing developer productivity.
- Domain-Specific NLP: Fine-tune for verticals like healthcare and finance, maintaining strong contextual understanding with manageable compute costs.
Apriel 5B in Action: Real World Example
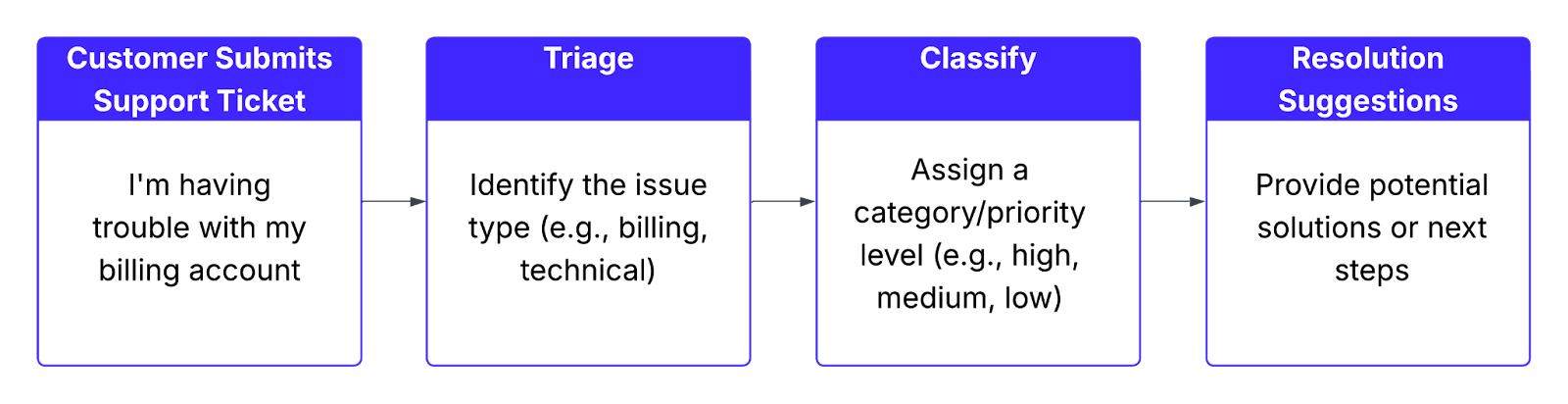
Imagine a customer support team that receives a high volume of tickets from customers. To ensure timely, effective resolutions, the team must:
- Triage: Identify the issue type (e.g., billing, technical, etc.)
- Classify: Assign a category or priority level (e.g., high, medium, low)
- Suggest Resolutions: Provide the customer with potential solutions or next steps
Code generated by Apriel 5B to automate this process
Here’s a Python example generated by Apriel 5B that uses spaCy and scikit-learn to classify support tickets and suggest resolutions:
import spacy
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
# Load the spaCy English model
nlp = spacy.load("en_core_web_sm")
# Define the support ticket data
support_tickets = [
("I'm having trouble with my billing account", "billing"),
("My device is not connecting to the internet", "technical"),
("I received an error message when trying to log in", "technical"),
("My account balance is low", "billing"),
("I need help with my account settings", "technical"),
]
# Create a pandas DataFrame
df = pd.DataFrame(support_tickets, columns=["ticket_text", "issue_type"])
# Define the TF-IDF vectorizer
vectorizer = TfidfVectorizer()
# Fit the vectorizer to the data and transform the text data into vectors
X = vectorizer.fit_transform(df["ticket_text"])
# Train a Naive Bayes classifier
clf = MultinomialNB()
clf.fit(X, df["issue_type"])
# Define a function to classify a new ticket
def classify_ticket(ticket_text):
# Transform the text data into a vector
vector = vectorizer.transform([ticket_text])
# Predict the issue type
predicted_issue_type = clf.predict(vector)[0]
return predicted_issue_type
# Test the function
new_ticket = "My device is not connecting to the internet"
predicted_issue_type = classify_ticket(new_ticket)
print(predicted_issue_type) # Output: "technical"
# Define a dictionary of potential solutions or next steps
potential_solutions = {
"billing": ["Please contact our billing team", "We will escalate your issue and get back to you within 24 hours"],
"technical": ["Please try the following steps: [list steps]", "Contact our technical support team for further assistance"]
}
# Define a function to provide potential solutions or next steps
def provide_solutions(predicted_issue_type):
if predicted_issue_type == "billing":
return potential_solutions["billing"]
elif predicted_issue_type == "technical":
return potential_solutions["technical"]
else:
return "We apologize, but we could not determine the issue type. Please contact our support team for further assistance."
# Test the function
predicted_issue_type = "technical"
next_steps = provide_solutions(predicted_issue_type)
print(next_steps)
Key Components:
- Text Processing: Loads the spaCy English model using
spacy.load("en_core_web_sm")for NLP preprocessing. - Data Preparation: Defines support tickets as tuples and creates a pandas DataFrame via
pd.DataFrame(). - Feature Extraction: Initializes
TfidfVectorizer(), then fits and transforms text data withvectorizer.fit_transform(). - Model Training: Creates a
MultinomialNB()classifier and trains it usingclf.fit()on the TF-IDF vectors and labels. - Classification Function: Defines
classify_ticket(ticket_text)which transforms new text withvectorizer.transform()and predicts the issue type usingclf.predict(). - Resolution Suggestion: Defines
provide_solutions(predicted_issue_type)that returns next steps based on predicted issue type from a predefined dictionary.
Why Apriel 5B Matters in 2025
As enterprises grapple with balancing AI innovation and operational cost, Apriel 5B demonstrates that well architected small LLMs deliver on-par performance with lower latency and reduced hardware requirements. This aligns with Gartner’s forecast that by 2027, organizations will prefer smaller, specialized AI models over large, general-purpose giants for business-critical tasks.
Apriel 5B was trained on Lambda and is hosted on Lambda Chat. It reflects our commitment to providing a seamless platform that supports end to end AI development lifecycle. This gives enterprises unrestricted freedom to train, experiment, fine-tune and deploy.
No contracts. No rate limits. Just pure, unleashed computing power.
-
We'd like to extend our gratitude to Lambda for its ongoing support. During the early phases, as we worked through various technical challenges, Lambda's dependable infrastructure and its responsive and knowledgeable team made all the difference.
The flexible access to compute provided by its GPU Flex Commitments, coupled with the performance of its 1-Click Clusters, allowed us to confidently push forward with experimentation and iteration—without concerns about the right compute access, downtime, or disruptions. We're grateful for Lambda's expertise and availability when we needed it most, and we truly value the reliability it's brought to the table

ServiceNow